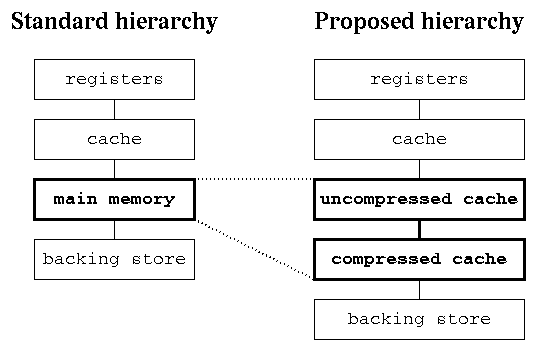
Compressed caching is the introduction of a new level into the virtual memory heirarchy. Specifically, RAM is used to store both an uncompressed cache of pages in their 'natural' encoding, and a compressed cache of pages in some compressed format. By using RAM to store some number of compressed pages, the effective size of RAM is increased, and so the number of page faults that must be serviced by very slow hard disks is decreased.
The paper on this topic was presented at the USENIX Annual Technical Conference '99, and you can grab a copy from the page of papers.
The programs in the test suite were each linked with VMTrace, our tracing utility. This utility works on SPARC-v8/Solaris and i386/Linux machines. (Note that new version of VMTrace are being developed with greater capabilities, but this version, under Linux, was the one used for our experiments in the paper.) For each page referenced, VMTrace outputs the page number, whether or not the page was dirtied, and a copy of the page image itself. The output of VMTrace was piped into our trace reduction utility. This utility creates a sequence that is the LRU behavior for a chosen reduction memory size, such that the larger the reduction memory, the smaller the resulting sequence. However, simulations must be performed on sequences (traces) reduced using a sufficiently small reduction memory to ensure accuracy. We have developed better reduction methods (SAD and OLR), but have not implemented them for page image traces. The LRU behavior trace created by the utility above contains page images, whose compressibility can be tested with our compressibility trace utility. Each page image in the source trace is measured, for a number of different compression algorithms, for compressibility, compression time, and decompression time. The result is an LRU behavior trace like the source trace, where the page images are replaced by compressibility measurements. Our size-adaptive compressed cache simulator accepts a compressibility trace as input, and simulates the management of a compression cache. It outputs the total paging time that would be required for a traditional VM system without compressed caching, and the total paging time required of a compressed caching VM system.
WK4x4 is the variant of our WK compression family that achieves the tighest compression by itself by using a 4x4 set-associative dictionary of recently seen words. WKdm compresses nearly as tightly as WK4x4, but is much faster because of the simple, direct-mapped dictionary of recently seen words. LZO is a very fast Lempel-Ziv implementation by Markus Oberhumer. LZRW1 was, until LZO, the reigning Lempel-Ziv speed champion, and was used in past studies on compressed caching.
From the programs listed in the test suite above, we gathered page image traces and reduced them on a memory size such that useful simulations could still be done, but the traces would be manageable to store and process. Note that these are very large, even though they have been reduced with our LRU behavior reduction utility and bzip2'ed as tightly as possible. If these are too large to grab, please send email to Scott Kaplan <sfkaplan@cs.amherst.edu>, and we can try to re-reduce the traces on a larger memory size to provide a smaller trace.
Page last updated on March
25, 2001
Send feedback to Scott Kaplan
<sfkaplan@cs.amherst.edu>